同技術は、画像をパッチ単位に分割し、3次元の位置情報を保持するパッチベース処理することで、各データセットの特徴を正確に学習でき、診断支援精度を3.04%向上させる優れものだ。
医療画像セグメンテーションタスクにおいて、画像を等サイズのパッチに分割し、三次元座標空間で表現するパッチベースの対照学習手法を導入した最初の取り組みとなる。データの種類に応じて専門モデルを動的に選ぶMixture of Expertsを導入し、異なる画像の干渉を回避しつつ高精度な医用画像セグメンテーションを実現した。
同技術は、多様な医用画像データを効率的に統合して学習できるAIモデルの実現に貢献し、限られた医療データでも高精度な診断支援を行う技術基盤として期待される。同研究成果は、国際学術誌「Neural Computing and Applications」に本年5月8日にオンライン公開された。
近年、医療現場ではAIによる画像診断支援の導入が進んでいるが、解像度やアノテーション(データへのタグ付け)方法が異なる複数の医療画像を、ひとつのAIで同時に扱うことは困難であった。
この課題に対し、画像を小さな領域(パッチ)に分けたうえで、それぞれのパッチが「どの医用画像データセット(網膜血管、腹部多臓器、など)」に属していて、「どの画像」の、「どの場所」のパッチであるかを3次元で保持する「パッチベースの学習法」と、データ種別ごとに専門的な処理を行う「Mixture of Experts(MoE)」を組み合わせた新手法「PatchMoE」を開発。体の部位が異なる4種の異なる医療画像を対象に検証を行い、従来手法を上回る精度を実現した。
医療画像における自動セグメンテーションは、診断支援や治療計画の精度向上を目的として広く研究されてきた。これまでの研究では、個別の医療タスクごとに専用のモデルを学習するアプローチが主流であった。だが、この手法はタスク間の知識共有が困難であり、モデルの冗長性や性能限界が課題となっていた。
特に、近年では、大規模な汎用モデルを事前学習させた上で、医療データへ転移学習する方法が注目されている。この方法により、大量のアノテーションを必要とせず、高い精度が得られることが確認されていたが、一般画像と医療画像の構造的違いにより、医療画像特有の詳細な特徴を十分に学習できない点が問題であった。
また、複数の医療データセットを統合して1つのモデルで学習させる場合、画像解像度の差やアノテーション基準の違いから、最適化の方向性が競合し合う「パレート効果」と呼ばれる問題が発生し、すべてのタスクで高い性能を同時に達成することが難しいとされていた。
こうした中、同研究では、解像度やアノテーション基準の異なる複数の医療画像データセットを、1つのモデルで統一的に学習できる新たな手法「PatchMoE(Patch-based Mixture of Experts)」を提案した。
これは、混合データセットに起因する学習の干渉や精度低下の問題を克服することを目指している。提案手法の主な構成要素は次の通り。
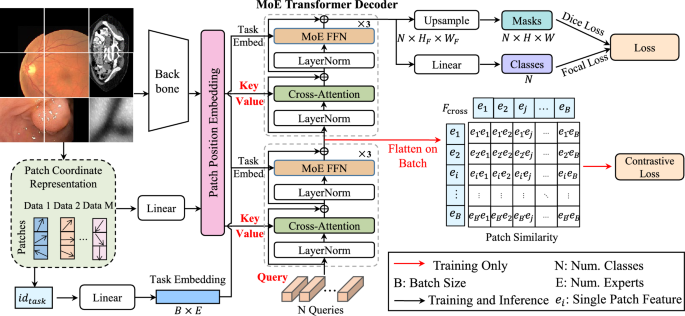
①パッチ分割と3次元パッチ位置表現(Patch Position Embedding:PPE)
PPEモジュールにより、画像を固定サイズの小領域(パッチ)に分割し、それぞれのパッチに「データセットID」「画像ID」「パッチID」の3次元情報を特徴空間に埋め込むことで、空間的・構造的な情報を保ったままTransformerベースのモデルに入力する。
これにより、異なる解像度の画像を扱う際にも空間的関係を維持し、コンテキスト理解を損なうことなく一貫した特徴抽出が可能となる。
②専門家混合型デコーダ(Mixture of Experts:MoE)
デコーダ部分において、データセットIDに基づいて稀疎な構造を持つMoE機構を導入し、各タスクに適した専門家ネットワークの組み合わせを動的に選択することで、マルチタスク学習における最適化の競合(パレート効果)を抑制する。
PatchMoEは医療画像分野で初めて、パッチベースのContrastive Learning(対照学習)を導入している。対照学習を用いることで、同一画像内の近接パッチの特徴を近づけ、異なる画像やデータセット間のパッチは区別するよう学習させている。
これにより、混合データセットにおけるパッチ間の文脈理解が促進され、特徴表現の精度が向上する。PatchMoEは、網膜血管(DRIVE)、近赤外血管(HVNIR)、消化器ポリープ(Kvasir-SEG)、腹部臓器(Synapse)の4種類のデータセットを用いた画像セグメンテーションにおいて検証され、既存の最先端手法(GCASCADE等)と比較して、平均Diceスコアで3.04%の精度向上を達成した。
同研究で提案したPatchMoEは、解像度や構造の異なる複数の医療画像を1つのモデルで統合的に解析できる点が特徴である。この技術により、特定の臓器や撮影条件に依存しない、より汎用的で柔軟な画像解析が可能となった。
今回、複数の代表的な医療画像データセット(眼底・手血管・消化器・腹部臓器)を用いて、その有効性を検証している。これにより、従来のように、各タスクに対して異なるAIモデルを用意する必要がなくなり、開発コストや医療データ活用の効率が大きく向上する可能性がある。
また、学習データが限られている疾患や施設間で画像仕様が異なるケースにおいても、同手法は高い適応性を示すことが確認されており、将来的には多施設間で共有可能な診断支援AIの基盤技術として活用が期待される。
CTやMRIなど3D画像への拡張が今後の課題
同研究で提案したPatchMoEは、異なる医療画像データセットに対して高精度なセグメンテーション性能を示しましたが、現状では各データセットに識別ID(dataset ID)を明示的に付与して処理を分けている。この仕組みは既知のデータセットには有効であるが、将来的に未知のデータやより細かなタスク分類への対応を目指すには、より柔軟で汎化可能な専門家選択手法の構築が必要である。
また、現行の検証は2D医療画像を対象としており、CTやMRIといった3D画像への拡張などについては今後の検討課題のひとつだ。これらに対応することで、PatchMoEはより幅広い医療応用への展開が可能となる。今後は、より多様なデータセットを用いた検証や、実医療環境下での臨床的有効性の評価も進めていく。
◆研究者のコメント
医療現場では、異なる解像度や注釈基準を持つ画像が日常的に扱われているが、それらを一つのAIモデルで解析するのは非常に困難であった。本研究では、複数の異なる画像を統合的に扱える新しい学習フレームワークPatchMoEを設計し、現実的な医療画像の多様性に対応できる可能性を示した。
今後は、より多様な画像形式や臨床現場での応用に向けて、実装と検証をさらに進めていきたいと考えている。

